Másodlagos indexek
Az elsődleges indexel, a fizikai elrendezés adta lehetőséget elhasználtuk. Ennek ellenére van lehetőségünk további indexek létrehozására. Nyilvánvalóan az e célra létrehozott segédstruktúrákat is tárolnunk kell, de mivel csak mutatókat fogunk tárolni az adatra, ezért az a tárhely igény a tábla méretéhez képest elhanyagolható.
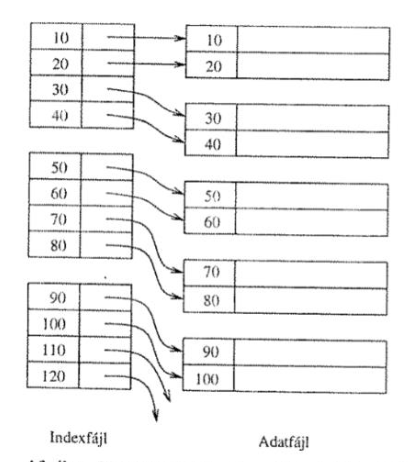
Sűrű index
Minden rekordot egy mutatót rendelünk, melyeket szekvenciálisan az adott oszlop(okban) szereplő értékek szerint rendezve tárolunk.
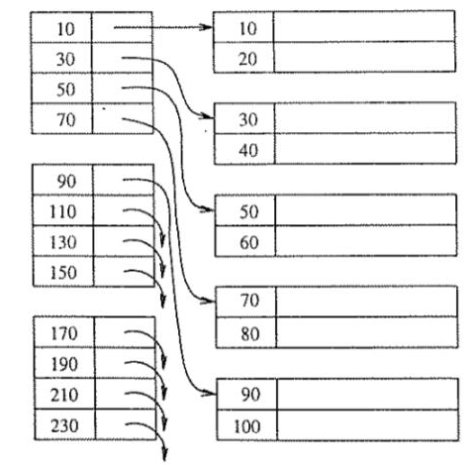
Ritka index
A sűrű indexhez nagyon hasonló, de rekordok helyett blokkokra tárolunk mutatókat. A rendezés alapjául szolgáló kulcs az adatblokkban szereplő első rekord megadott oszlopának (esetleg oszlopainak) értéke.
Többszintű index
Az indexre is tudunk indexet készítene, mellyel tovább tudjuk növelni a hatékonyságot.
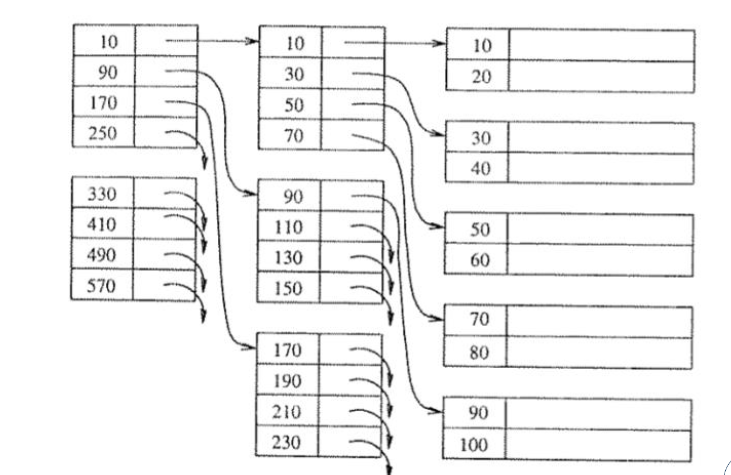
Többszintű index esetén csak az alsó szint lehet sűrű. Ez logikus, hiszen bármely azonos oszlopra készített sűrű index pontosan ugyanazokat a mutatókat tartalmazza (legfeljebb a sorrendjük tér el [stabil rendezés esetén még ez sem]).
Indexek tárhelyigénye
Az indexek tárhelyigényének vizsgálatához vezessük be a következő fogalmakat:
- : az reláció sorainak száma
- : az reláció tárolásához szükséges blokkok száma
- blokkolási faktor:
- : azt adja meg az reláció hány sora fér el egy blokkban
- : azt adja meg az index hány kulcs-érték párja fér el egy blokkban
Legyen táblák, sűrű és ritka indexek úgy, hogy , , , . Számoljuk ki hány blokk szükséges az említett struktúrák tárolásához.
Mivel egy sűrű index ezért mind a 10000 rekordra el kell tárolnunk 1-1 mutatót:
Mivel egy irtka index ezért minden blokkra kell csak mutatót tárolnunk:
Oldjuk meg az előző feladatot úh, hogy csak a blokkok -a legyen tele!
Ez pontosan azt jelenti, hogy -al kevesebb rekord vagy kulcs-mutató pár fér egy blokkba. Így , , .
Tároláshoz mindig egész blokkok vannak használva, tehát ha egy index mérete 7,0005 blokk lenne az index ténylegesen 8 blokkot fog elfoglalni.
:::